"A Ascensão dos Agentes Autônomos em 2025" explora padrões práticos, plataformas e considerações de...
Como evitar falhas críticas em lançamentos de software
Um guia prático e baseado em framework para lançamentos de software mais seguros. Aprenda como sinalizadores de funcionalidades, implantações canárias, estratégias azul/verde, observabilidade e postmortems sem culpa reduzem riscos e melhoram a confiabilidade do lançamento.
Introdução
Lançar software sem surpresas é um objetivo compartilhado por equipes de produto, engenheiros e stakeholders. Mesmo pequenas alterações podem resultar em falhas críticas se não forem lançadas com planejamento disciplinado, testes robustos e forte observabilidade. Este guia apresenta uma abordagem prática e baseada em framework para reduzir riscos em lançamentos de software — combinando planejamento de lançamento, estratégias de implantação canário e azul/verde, governança de sinalizadores de recursos e uma cultura de postmortems sem culpa. Baseadas em práticas comprovadas do setor, essas etapas ajudam você a lançar mais rapidamente, protegendo o tempo de atividade, a integridade dos dados e a experiência do usuário.
1. Crie uma estrutura formal de prontidão para lançamento
Um lançamento seguro começa muito antes do código chegar à produção. Crie uma Lista de Verificação de Prontidão para Lançamento que abranja pessoas, processos e prontidão técnica. Os principais elementos incluem:
- Avaliação de escopo e risco: defina quais alterações estão incluídas, as áreas de impacto potencial (modelos de dados, integrações, segurança) e os modos de falha.
- Plano de rollback/kill switch: especifique as etapas exatas para reverter ou redirecionar o tráfego caso as métricas se deteriorem.
- Requisitos de observabilidade: garanta que painéis, alertas, logs, rastreamentos e verificações sintéticas estejam em vigor para detectar anomalias minutos após o lançamento.
- Estratégia de migração de dados: planeje alterações de esquema compatíveis com versões anteriores e a semeadura de dados para preparação e produção, conforme necessário.
- Plano de implementação e gates: decida quanto tráfego expor em cada estágio e o que constitui um estágio bem-sucedido antes de avançar.
Implantações menores e com escopo bem definido, com gates automatizados, ajudam a evitar lançamentos "big-bang" que são difíceis para reverter. Essa prática está alinhada aos princípios da engenharia de lançamento, que enfatizam compilações reproduzíveis, implantações automatizadas e pequenas alterações independentes.
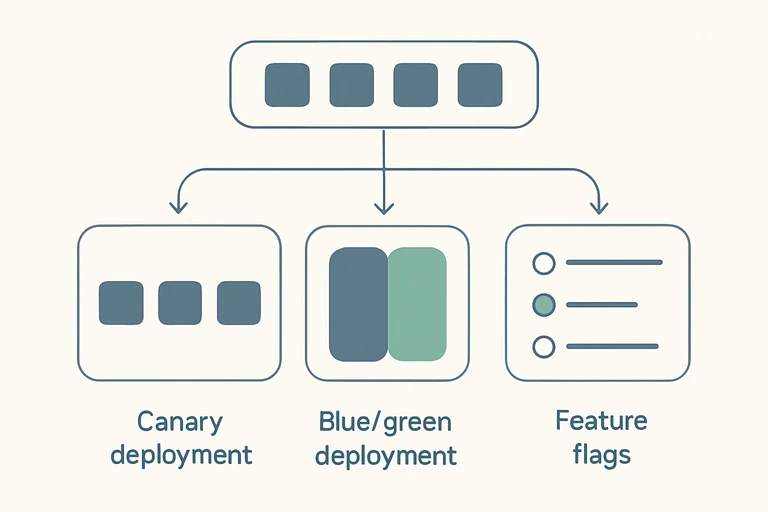
2. Use sinalizadores de recursos para desacoplar a implantação da versão
Os sinalizadores de recursos são uma ferramenta essencial para controlar a experiência do usuário sem alterar os caminhos do código. Eles permitem implementações em fases, reversões rápidas e experimentação direcionada. Aplique estas práticas recomendadas:
- Mantenha os sinalizadores focados: envolva um único recurso ou uma pequena alteração coesa em um sinalizador para reduzir a complexidade.
- Planeje rollback e fallback: garanta que haja um caminho padrão seguro se o sinalizador estiver desativado ou se o recurso se comportar de forma inesperada.
- Nomeie e gerencie os sinalizadores de forma consistente: adote convenções claras (por exemplo,
FeatureXEnabled, sem frases negativas), centralize as definições dos sinalizadores e documente as expectativas. - Implemente gradualmente: comece com usuários internos, depois com um grupo beta e, por fim, com públicos mais amplos. Monitore as métricas e pause ou reverta se os limites forem violados.
- Limpe os sinalizadores regularmente: remova sinalizadores não utilizados ou obsoletos para reduzir a dívida técnica.
- Use uma plataforma de gerenciamento de sinalizadores sempre que possível: escolha uma ferramenta adequada à sua equipe e que ofereça auditoria, acesso baseado em funções e alternância fácil.
Essas práticas apoiam o aprendizado no estilo canário e a experimentação controlada, minimizando os raios de explosão e permitindo uma reação mais rápida quando surgem problemas. Pesquisas e orientações de profissionais destacam consistentemente o valor dos sinalizadores de recursos em lançamentos incrementais e seguros.
3. Implantações canário: exponha o risco a uma pequena parcela do tráfego
Uma implantação canário apresenta a nova versão a uma parcela limitada de usuários ou tráfego, permitindo a validação no mundo real com impacto mínimo. Diretrizes práticas:
- Defina uma população canário: comece com uma amostra pequena e representativa (por exemplo, 1–5%) e planeje aumentar gradualmente conforme a confiança aumenta.
- Automatize as mudanças e reversões de tráfego: use a modelagem de tráfego e a reversão automatizada se as métricas principais ultrapassarem os limites predefinidos.
- Monitore de forma abrangente: acompanhe as taxas de erro, latência, saturação e métricas críticas de negócios. Compare com o grupo de controle para detectar regressões precocemente.
- Isole onde possível: garanta que o tráfego canário não afete negativamente os backends ou dados compartilhados; isole os experimentos para evitar falhas transversais.
As implantações canário reduzem o risco ao detectar defeitos em cargas de trabalho reais, limitando a exposição. Quando implementadas com reversões automatizadas e forte observabilidade, elas fornecem um ciclo de feedback rápido que suporta o aprendizado rápido da engenharia. As práticas de canarying do Google enfatizam implantações automatizadas e pequenas, além de progresso mensurável, reforçando o valor de lançamentos controlados e baseados em dados.
4. Implantações Azul/Verde: transição segura com capacidade de reversão instantânea
As implantações Azul/Verde mantêm dois ambientes de produção em execução paralela: o atual (azul) e o novo (verde). O tráfego é transferido do azul para o verde quando a nova versão é validada. Essa abordagem minimiza o tempo de inatividade e simplifica a reversão. As melhores práticas incluem:
- Infraestrutura como código (IaC): manter ambos os ambientes com configurações idênticas para garantir comportamento consistente e configurações reproduzíveis.
- Estratégia de dados: desvincular as alterações de esquema do código sempre que possível; Garanta a compatibilidade com versões anteriores ou planeje uma migração de dados em fases para que a versão antiga ainda possa operar caso seja necessário reverter a versão.
- Validação automatizada e mudança de tráfego: automatize verificações de integridade, testes de fumaça e roteamento de tráfego, incluindo um caminho de reversão rápido caso sejam detectados problemas.
- Segurança e conformidade em trânsito: garanta que os controles de acesso e as trilhas de auditoria sejam consistentes em ambos os ambientes durante a transição.
Implantações Blue/Green são particularmente eficazes para sistemas de alta disponibilidade, onde até mesmo interrupções curtas são inaceitáveis. Quando a sincronização de dados e alterações de esquema estão envolvidas, as abordagens descritas nas práticas recomendadas da AWS enfatizam a compatibilidade com versões anteriores e o planejamento cuidadoso para minimizar os riscos durante a transição.
5. Observabilidade e resposta automatizada: detecte, diagnostique e recupere rapidamente
A observabilidade é a espinha dorsal de lançamentos seguros. Crie um ambiente orientado a painéis e pronto para resposta que ofereça suporte a:
- Métricas e rastreamentos em tempo real: capture latência, taxas de erro, saturação e integridade das dependências em todos os serviços.
- Alertas automatizados vinculados a SLOs: configure alertas que respeitem seus orçamentos de erro; evite a fadiga de alertas alinhando os limites com o impacto nos negócios.
- Reversão ou promoção automatizada: quando canários ou testes azul/verde atendem aos critérios de sucesso, promova automaticamente; se as métricas ultrapassarem os limites, reverta sem esforço manual.
- Monitoramento sintético e experiência do usuário final: verificações sintéticas complementam dados reais do usuário para verificar se os caminhos críticos permanecem íntegros.
Essa ênfase na observabilidade e nas respostas automatizadas reduz o tempo médio de detecção e recuperação, um fator crucial para evitar que um pequeno bug se transforme em uma interrupção crítica. As orientações do setor ressaltam a importância do monitoramento durante os lançamentos canários e de produção, bem como o valor de reversões automatizadas e mudanças de tráfego em etapas.
6. Validação pré-lançamento: testes alinhados às condições do mundo real
A validação completa do pré-lançamento reduz surpresas na produção. As etapas práticas incluem:
- Testes em ambientes semelhantes aos de produção: garanta que o staging espelhe a produção em termos de distribuição de dados, características de carga e interações com terceiros, sempre que possível.
- Testes de dados e migração: valide a compatibilidade com versões anteriores das alterações no banco de dados e verifique a integridade dos dados após as migrações.
- Testes de ponta a ponta e de caos: execute cenários de ponta a ponta e experimentos de caos guiados para entender os modos de falha em condições controladas.
- Verificações de segurança e privacidade: valide se as alterações na versão não introduzem novas vulnerabilidades ou exposição de dados.
Integre testes automatizados com CI/CD para garantir que cada artefato de versão passe por um rigoroso processo de verificação antes da implantação. A ideia é deslocar os testes para a esquerda, mantendo o pipeline de implantação automatizado e auditável.
7. Postmortems sem culpa: aprendendo com cada lançamento
Mesmo com as melhores práticas, incidentes acontecem. O segredo é tratar as falhas como oportunidades de aprendizado, não como falhas pessoais. Uma estrutura de postmortem sem culpa ajuda as equipes a identificar as causas-raiz, melhorias acionáveis e mudanças preventivas sem apontar culpados. As práticas essenciais incluem:
- Critérios de gatilho: defina gatilhos claros para análises retrospectivas (por exemplo, tempo de inatividade visível ao usuário, perda crítica de dados ou reversão manual).
- Análise de causa raiz (ACR): investigue profundamente fatores sistêmicos, não individuais, para descobrir lacunas de processo, limitações de ferramentas ou fragilidades arquitetônicas.
- Acompanhamentos acionáveis: atribua responsáveis e cronogramas para melhorias concretas e, em seguida, acompanhe o progresso publicamente.
- Cultura de aprendizagem: compartilhe lições amplamente para evitar recorrências entre equipes e produtos.
O Google SRE enfatiza uma cultura de análise retrospectiva sem culpa como base da confiabilidade, incentivando a colaboração, o compartilhamento aberto e a melhoria contínua. Essa cultura ajuda a reduzir a recorrência e a melhorar a preparação para lançamentos futuros.
8. Projeto prático de implementação: um exemplo passo a passo
Aqui está um projeto concreto que você pode adaptar para um produto web típico com um novo conjunto de recursos:
- Defina o escopo e os critérios de sucesso da versão: enumere alterações, dependências e métricas críticas (taxa de erro, latência, impacto na receita).
- Prepare mecanismos de rollback e kill switch: implemente etapas de rollback automatizadas e caminhos rápidos de redirecionamento de tráfego.
- Implemente sinalizadores de recursos para os novos recursos: envolva as alterações por trás dos sinalizadores, documente as expectativas e planeje a implementação gradual.
- Execute canários com tráfego em fases: exponha 1 a 2% do tráfego, monitore as principais métricas e aumente gradualmente, se for seguro.
- Mude para azul/verde, se possível: implante o ambiente verde em paralelo e transfira o tráfego somente após a validação; Mantenha a compatibilidade com versões anteriores para rollback.
- Monitore e responda automaticamente: use alertas vinculados a SLOs; automatize o rollback se os limites forem ultrapassados e promova-o se positivo.
- Conduza um postmortem após a estabilização: capture aprendizados, atualize runbooks e comunique melhorias.
Com essas etapas, você cria um pipeline de lançamento que enfatiza segurança, velocidade e aprendizado — princípios que sustentam a entrega confiável de software.
Conclusão
Reduzir o risco de falhas críticas em lançamentos de software não significa desacelerar; trata-se de lançar com disciplina, visibilidade e uma cultura de aprendizado. Ao combinar uma estrutura formal de prontidão para lançamento, uso disciplinado de sinalizadores de recursos, implantações canário e azul/verde controladas, forte observabilidade, validação completa de pré-lançamento e postmortems sem culpa, as equipes podem entregar software mais rapidamente, protegendo os usuários e os resultados de negócios. Essa abordagem está alinhada às diretrizes estabelecidas do setor sobre engenharia de lançamento, implantações canárias e aprendizado de incidentes, e fornece um caminho prático para equipes de qualquer tamanho elevarem sua maturidade em lançamentos. A Multek defende essas práticas como uma forma de entregar software seguro e de alta qualidade com rapidez, mantendo operações éticas, centradas no usuário e confiáveis.
Você também pode gostar

O DevOps está ao alcance das PMEs. Este guia prático descreve uma abordagem enxuta e orientada a val...
Proteger APIs contra vazamentos exige uma abordagem de defesa em profundidade: autenticação forte, a...